Monitoring und Logging für Webanwendungen

Warum Monitoring und Logging unverzichtbar sind
Eine Webanwendung in Produktion ohne Monitoring zu betreiben, ist wie Autofahren ohne Armaturenbrett. Probleme werden erst bemerkt, wenn Nutzer sich beschweren – und dann ist es oft zu spät. Professionelles Monitoring und strukturiertes Logging ermöglichen es, Probleme frühzeitig zu erkennen und zu beheben.
Monitoring: Metriken und Alerting
Prometheus und Grafana
Prometheus ist der De-facto-Standard für Metriken-Sammlung in modernen Infrastrukturen. Es verwendet ein Pull-basiertes Modell und speichert Zeitreihendaten effizient. In Kombination mit Grafana entstehen aussagekräftige Dashboards.
Typische Metriken, die überwacht werden sollten:
- Request Rate: Anfragen pro Sekunde
- Error Rate: Anteil fehlerhafter Antworten (4xx, 5xx)
- Latenz: Antwortzeiten (p50, p95, p99)
- Saturation: CPU-, RAM- und Disk-Auslastung
Die vier goldenen Signale des Monitorings: Latenz, Traffic, Fehlerrate und Sättigung. Wer diese vier Metriken im Blick hat, erkennt die meisten Probleme frühzeitig.
Alerting richtig konfigurieren
Alerts sollten actionable sein – jeder Alert sollte eine klare Handlung auslösen. Zu viele Alerts führen zu Alert-Fatigue, zu wenige lassen Probleme unentdeckt. Bewährte Regeln:
- Alerts auf Symptome setzen, nicht auf Ursachen
- Severity-Level definieren: Critical, Warning, Info
- Eskalationsketten einrichten
- Regelmäßig Alert-Regeln überprüfen und anpassen
Logging: Strukturiert und zentralisiert
Der ELK Stack
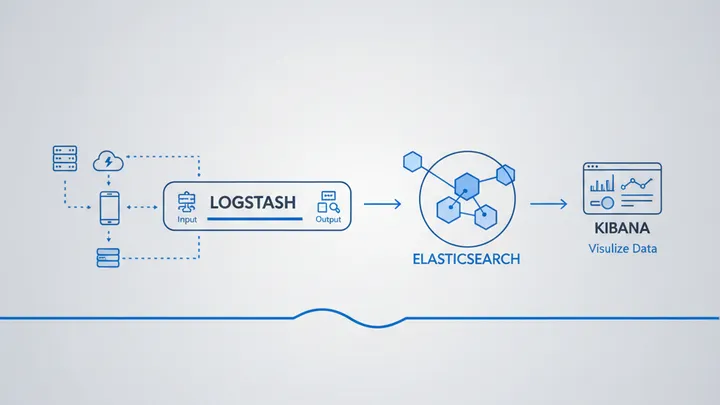
Der ELK Stack – Elasticsearch, Logstash und Kibana – ist die bekannteste Lösung für zentralisiertes Logging. Logs werden von Logstash gesammelt und verarbeitet, in Elasticsearch gespeichert und über Kibana visualisiert und durchsucht.
Strukturiertes Logging
Unstrukturierte Logs sind schwer zu durchsuchen und zu analysieren. Stattdessen sollten Logs als JSON geschrieben werden:
{"timestamp":"2025-06-23T10:15:00Z","level":"error","service":"api","message":"Database connection failed","duration_ms":5000}
- Timestamp: ISO 8601 Format
- Level: debug, info, warn, error, fatal
- Service: Welcher Dienst hat den Log erzeugt
- Correlation ID: Zum Verfolgen von Requests über mehrere Services
Error Tracking mit Sentry
Für Frontend- und Backend-Fehler bietet Sentry eine spezialisierte Lösung. Fehler werden automatisch erfasst, gruppiert und mit Kontext angereichert – Stacktraces, Browser-Informationen, Benutzeraktionen und mehr.
Monitoring bei Hetzner und Co.
Wer seine Anwendungen bei Hetzner hostet, kann Prometheus und Grafana als Docker-Container neben der Anwendung betreiben. Für kleinere Setups reicht oft auch ein einfaches Health-Check-Monitoring mit Tools wie Uptime Kuma.
Best Practices
- Log-Rotation: Logs regelmäßig rotieren und alte Logs archivieren
- Keine sensiblen Daten loggen: Passwörter, Tokens und personenbezogene Daten gehören nicht in Logs
- Dashboards für verschiedene Zielgruppen: Entwickler brauchen andere Metriken als das Management
- Runbooks erstellen: Dokumentation der Schritte bei bekannten Problemen
- Monitoring testen: Regelmäßig prüfen, ob Alerts ausgelöst werden
Fazit
Monitoring und Logging sind keine optionalen Extras, sondern grundlegende Bestandteile einer professionellen Infrastruktur. Die Kombination aus Metriken (Prometheus/Grafana), zentralisiertem Logging (ELK Stack) und Error Tracking (Sentry) bietet einen umfassenden Überblick über den Zustand der Anwendung. Investieren Sie früh in Observability – es zahlt sich bei jedem Incident aus.
Ihre Infrastruktur professionell aufsetzen
Vereinbaren Sie ein kostenloses Erstgespräch – wir beraten Sie persönlich und unverbindlich.
Kostenloses Erstgespräch vereinbarenVerwandte Artikel
 DevOps
DevOps Linux-Server-Administration: Grundlagen für Entwickler
Grundlegende Linux-Server-Administration gehört zum Handwerkszeug jedes Entwicklers. Dieser Leitfaden vermittelt die wichtigsten Konzepte und Befehle für den sicheren Serverbetrieb.
 DevOps
DevOps Kubernetes für Einsteiger: Container-Orchestrierung verstehen
Kubernetes ist der Standard für Container-Orchestrierung. Dieser Einsteiger-Guide erklärt die Grundkonzepte und hilft beim Start in die Welt der Container-Verwaltung.
 DevOps
DevOps CI/CD-Pipelines: Automatisiertes Deployment einrichten
Manuelle Deployments sind fehleranfällig und zeitaufwändig. Mit CI/CD-Pipelines automatisieren Sie den gesamten Prozess vom Code-Commit bis zur Produktion.
 DevOps
DevOps Web-Performance-Optimierung: Ladezeiten halbieren
Langsame Websites kosten Besucher und Umsatz. Wir zeigen konkrete Maßnahmen, mit denen Sie die Ladezeiten Ihrer Webanwendung drastisch reduzieren können.